Monday, October 24, 2016
How We Architected and Run Kubernetes on OpenStack at Scale at Yahoo! JAPAN
_Editor’s note: today’s post is by the Infrastructure Engineering team at Yahoo! JAPAN, talking about how they run OpenStack on Kubernetes. This post has been translated and edited for context with permission – originally published on the Yahoo! JAPAN engineering blog. _
Intro
This post outlines how Yahoo! JAPAN, with help from Google and Solinea, built an automation tool chain for “one-click” code deployment to Kubernetes running on OpenStack.
We’ll also cover the basic security, networking, storage, and performance needs to ensure production readiness.
Finally, we will discuss the ecosystem tools used to build the CI/CD pipeline, Kubernetes as a deployment platform on VMs/bare metal, and an overview of Kubernetes architecture to help you architect and deploy your own clusters.
Preface
Since our company started using OpenStack in 2012, our internal environment has changed quickly. Our initial goal of virtualizing hardware was achieved with OpenStack. However, due to the progress of cloud and container technology, we needed the capability to launch services on various platforms. This post will provide our example of taking applications running on OpenStack and porting them to Kubernetes.
Coding Lifecycle
The goal of this project is to create images for all required platforms from one application code, and deploy those images onto each platform. For example, when code is changed at the code registry, bare metal images, Docker containers and VM images are created by CI (continuous integration) tools, pushed into our image registry, then deployed to each infrastructure platform.

We use following products in our CICD pipeline:
| Function | Product |
|---|---|
| Code registry | GitHub Enterprise |
| CI tools | Jenkins |
| Image registry | Artifactory |
| Bug tracking system | JIRA |
| deploying Bare metal platform | OpenStack Ironic |
| deploying VM platform | OpenStack |
| deploying container platform | Kubernetes |
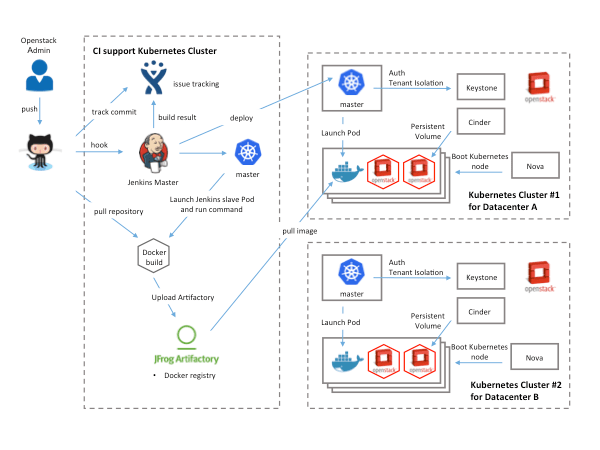
Image Creation. Each image creation workflow is shown in the next diagram.
VM Image Creation :

- 1.push code to GitHub
- 2.hook to Jenkins master
- 3.Launch job at Jenkins slave
- 4.checkout Packer repository
- 5.Run Service Job
- 6.Execute Packer by build script
- 7.Packer start VM for OpenStack Glance
- 8.Configure VM and install required applications
- 9.create snapshot and register to glance 10.10.Download the new created image from Glance 11.11.Upload the image to Artifactory
Bare Metal Image Creation:

- 1.push code to GitHub
- 2.hook to Jenkins master
- 3.Launch job at Jenkins slave
- 4.checkout Packer repository
- 5.Run Service Job
- 6.Download base bare metal image by build script
- 7.build script execute diskimage-builder with Packer to create bare metal image
- 8.Upload new created image to Glance
- 9.Upload the image to Artifactory
Container Image Creation:

- 1.push code to GitHub
- 2.hook to Jenkins master
- 3.Launch job at Jenkins slave
- 4.checkout Dockerfile repository
- 5.Run Service Job
- 6.Download base docker image from Artifactory
- 7.If no docker image found at Artifactory, download from Docker Hub
- 8.Execute docker build and create image
- 9.Upload the image to Artifactory
Platform Architecture.
Let’s focus on the container workflow to walk through how we use Kubernetes as a deployment platform. This platform architecture is as below.

| Function | Product |
|---|---|
| Infrastructure Services | OpenStack |
| Container Host | CentOS |
| Container Cluster Manager | Kubernetes |
| Container Networking | Project Calico |
| Container Engine | Docker |
| Container Registry | Artifactory |
| Service Registry | etcd |
| Source Code Management | GitHub Enterprise |
| CI tool | Jenkins |
| Infrastructure Provisioning | Terraform |
| Logging | Fluentd, Elasticsearch, Kibana |
| Metrics | Heapster, Influxdb, Grafana |
| Service Monitoring | Prometheus |
We use CentOS for Container Host (OpenStack instances) and install Docker, Kubernetes, Calico, etcd and so on. Of course, it is possible to run various container applications on Kubernetes. In fact, we run OpenStack as one of those applications. That’s right, OpenStack on Kubernetes on OpenStack. We currently have more than 30 OpenStack clusters, that quickly become hard to manage and operate. As such, we wanted to create a simple, base OpenStack cluster to provide the basic functionality needed for Kubernetes and make our OpenStack environment easier to manage.
Kubernetes Architecture
Let me explain Kubernetes architecture in some more detail. The architecture diagram is below.
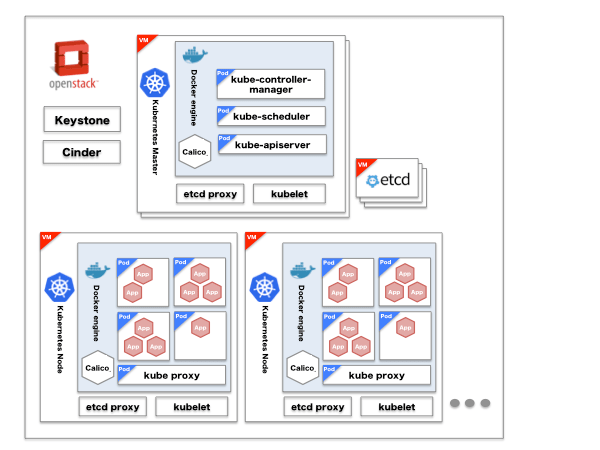
|Product |Description | |OpenStack Keystone|Kubernetes Authentication and Authorization | |OpenStack Cinder |External volume used from Pod (grouping of multiple containers) | |kube-apiserver |Configure and validate objects like Pod or Services (definition of access to services in container) through REST API| |kube-scheduler |Allocate Pods to each node | |kube-controller-manager |Execute Status management, manage replication controller | |kubelet |Run on each node as agent and manage Pod | |calico |Enable inter-Pod connection using BGP | |kube-proxy |Configure iptable NAT tables to configure IP and load balance (ClusterIP) | |etcd |Distribute KVS to store Kubernetes and Calico information | |etcd-proxy |Run on each node and transfer client request to etcd clusters|
Tenant Isolation To enable multi-tenant usage like OpenStack, we utilize OpenStack Keystone for authentication and authorization.
Authentication With a Kubernetes plugin, OpenStack Keystone can be used for Authentication. By Adding authURL of Keystone at startup Kubernetes API server, we can use OpenStack OS_USERNAME and OS_PASSWORD for Authentication. Authorization We currently use the ABAC (Attribute-Based Access Control) mode of Kubernetes Authorization. We worked with a consulting company, Solinea, who helped create a utility to convert OpenStack Keystone user and tenant information to Kubernetes JSON policy file that maps Kubernetes ABAC user and namespace information to OpenStack tenants. We then specify that policy file when launching Kubernetes API Server. This utility also creates namespaces from tenant information. These configurations enable Kubernetes to authenticate with OpenStack Keystone and operate in authorized namespaces. Volumes and Data Persistence Kubernetes provides “Persistent Volumes” subsystem which works as persistent storage for Pods. “Persistent Volumes” is capable to support cloud-provider storage, it is possible to utilize OpenStack cinder-volume by using OpenStack as cloud provider. Networking Flannel and various networking exists as networking model for Kubernetes, we used Project Calico for this project. Yahoo! JAPAN recommends to build data center with pure L3 networking like redistribute ARP validation or IP CLOS networking, Project Calico matches this direction. When we apply overlay model like Flannel, we cannot access to Pod IP from outside of Kubernetes clusters. But Project Calico makes it possible. We also use Project Calico for Load Balancing we describe later.
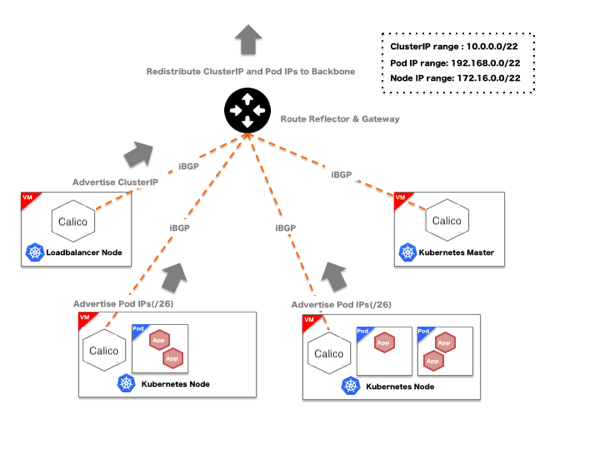
In Project Calico, broadcast production IP by BGP working on BIRD containers (OSS routing software) launched on each nodes of Kubernetes. By default, it broadcast in cluster only. By setting peering routers outside of clusters, it makes it possible to access a Pod from outside of the clusters. External Service Load Balancing
There are multiple choices of external service load balancers (access to services from outside of clusters) for Kubernetes such as NodePort, LoadBalancer and Ingress. We could not find solution which exactly matches our requirements. However, we found a solution that almost matches our requirements by broadcasting Cluster IP used for Internal Service Load Balancing (access to services from inside of clusters) with Project Calico BGP which enable External Load Balancing at Layer 4 from outside of clusters.

Service Discovery
Service Discovery is possible at Kubernetes by using SkyDNS addon. This is provided as cluster internal service, it is accessible in cluster like ClusterIP. By broadcasting ClusterIP by BGP, name resolution works from outside of clusters. By combination of Image creation workflow and Kubernetes, we built the following tool chain which makes it easy from code push to deployment.
Summary
In summary, by combining Image creation workflows and Kubernetes, Yahoo! JAPAN, with help from Google and Solinea, successfully built an automated tool chain which makes it easy to go from code push to deployment, while taking multi-tenancy, authn/authz, storage, networking, service discovery and other necessary factors for production deployment. We hope you found the discussion of ecosystem tools used to build the CI/CD pipeline, Kubernetes as a deployment platform on VMs/bare-metal, and the overview of Kubernetes architecture to help you architect and deploy your own clusters. Thank you to all of the people who helped with this project. –Norifumi Matsuya, Hirotaka Ichikawa, Masaharu Miyamoto and Yuta Kinoshita. _This post has been translated and edited for context with permission – originally published on the Yahoo! JAPAN engineer blog where this was one in a series of posts focused on Kubernetes._